92 KiB
| header-includes | lang | ||||
|---|---|---|---|---|---|
|
fr |
\newcommand{\hrq}{ \rule{.25\textwidth}{1pt} }
\def\authorshort{SPRIGGS} \def\authorlong{Julia \authorshort} \def\dateshort{2024} \def\datelong{Lundi 04 Novembre \dateshort} \def\titleshort{Oros} \def\titlelong{\titleshort : location de matériel de montagne}
\setcounter{secnumdepth}{3} \setcounter{tocdepth}{3}
\setmainfont{DejaVu Sans} \setmonofont{DejaVu Sans Mono}
\setlist{topsep=1em, left=1em} \renewcommand{\tightlist}{\setlength{\itemsep}{.5em}}
\begin{center} {\bfseries \begin{large}
\includegraphics[height=8cm]{images/oros}
\begin{huge} \titlelong
\vspace{1em}
\authorlong \end{huge}
\vfill
\includegraphics[height=2cm]{images/wcs}
{\larger[2] W}ILD {\larger[2] C}ODE {\larger[2] S}CHOOL \hrq Bordeaux
\vfill
Dossier de projet\ présenté en vue d’obtenir le titre :
« Concepteur développeur d’applications web » \hrq Soutenu le :
\datelong
\end{large} } \end{center} \thispagestyle{empty} \pagebreak
\tableofcontents \pagebreak
Liste des Compétences du référentiel
-
Développer une application sécurisée
- Installer et configurer son environnement de travail en fonction du projet
- Développer des interfaces utilisateur
- Développer des composants métier
- Contribuer à la gestion d’un projet informatique
-
Concevoir et développer une application sécurisée organisée en couches
- Analyser les besoins et maquetter une application
- Définir l’architecture logicielle d’une application
- Concevoir et mettre en place une base de données relationnelle
- Développer des composants d’accès aux données SQL et NoSQL
-
Préparer le déploiement d’une application sécurisée
- Préparer et exécuter les plans de tests d’une application
- Préparer et documenter le déploiement d'une application
- Contribuer à la mise en production dans une démarche DevOps
\newpage
Abstract
While working on my undergraduate degree with the Wild Code School, I worked on a project where we had to create a full stack web application from the ground up, from conception to deployment with a group of three other people. We called our fictional rental equipment company Oros, as it means mountain in ancient Greek, and our company specializes in mountain sports. The goal for us was to create a simple and intuitive site to manage rentals as well as the store’s inventory.
Here are the main features of the application:
- Admin login with access to the back office
- Back office management of inventory as well as the product references (name, description, and image)
- Back office: ability to see reservations
- Front office: searching for available products by name, category, and date range
- Front office: a shopping cart with options to add, remove, or update the quantity of selected products
- Front office: cart summary and billing information for checkout, with order processing through a mock payment system
Our project followed the AGILE method.
We used NodeJs along with ExpressJs, and ApolloServer to manage GraphQL queries on the back-end. TypeGraphQL was used to help define schemas and data types. We made the decision to use PostgreSQL for our database, and TypeORM was used to help manage its data. We used NextJs in conjunction with React for the front-end. Our Layout was done with CSS and Material UI. Our entire project was written in Typescript.
As our group’s application was being maintained on Github, we used Github actions to update our images each time new code was pushed to main on our back-end or front-end repositories. With each build, our tests (using Jest and Cypress) were executed, and if they passed, the newest image was published to our group’s dockerhub. We then were able to use webhooks which we created to fetch the latest image, and deploy it on our production site or our pre-production (staging) site.
\newpage
Cahier des charges
Contexte et définition du projet
L’entreprise Oros est un magasin spécialisé dans la location de biens pour diverses activités en montagne. Ainsi, elle doit gérer ses stocks et ses réservations de manière fiable. Pour cette raison, l’entreprise aurait besoin d’une application web qui gère ces deux besoins en parallèle afin de faciliter leur organisation.
Objectifs du projet
Au niveau administrateur, il faut gérer les références produits ainsi que le nombre d’exemplaires en stock. Il devrait également pouvoir consulter les réservations qui ont été effectuées par les clients. Pour les clients qui utilisent le site, ils devraient pouvoir rechercher les produits disponibles, gérer leur panier avec la possibilité d’ajouter, retirer ou modifier le nombre de produits sélectionnés. Un récapitulatif du panier et la saisie des informations de facturation sera disponible, ainsi qu’un passage de commande et une validation finale par paiement.
Les rôles
Un visiteur du site peut voir tous les produits disponibles pour réservation. Une fois son compte créé, il peut réserver les produits choisis pour les dates sélectionnées. Seul un administrateur peut créer des nouveaux produits, en supprimer ou modifier si besoin, ainsi que consulter toutes les réservations en cours. Un utilisateur ne peut accéder à la partie administrative, mais un administrateur a accès à toutes les rubriques du site.
Structure et fonctionnalités
Le site est composé de deux parties : back-office et front-office. Le back-office concerne seulement l’administrateur. Il permet la gestion des références produits ainsi que la consultation des réservations et du nombre d’exemplaires en stock. L’administrateur contrôle le nombre, le nom, la description et l’image de chaque produit qui apparaît sur le site. Il peut en outre retirer du catalogue tout produit rendu endommagé. Le front-office concerne ce qu’un visiteur ou un client peuvent voir. Pour un simple visiteur, il peut consulter les produits qui sont disponibles en magasin. Un client peut non seulement consulter les produits, mais il peut également s’authentifier sur le site, ajouter des produits dans son panier, puis en retirer ou modifier si besoin. Une fois décidé, il peut consulter un récapitulatif de son panier, puis créer une réservation pour les produits sélectionnés et finaliser la réservation par paiement.
Technologies et outils tiers
Pour le back-end, nous utilisons :
- NodeJs et ExpressJs, pour établir le serveur
- ApolloServer, pour gérer les requêtes GraphQL
- TypeGraphQL, pour définir les schémas et les types de données
- TypeORM, pour la gestion de données
- PostgreSQL, pour la base de données
Pour le front-end, nous utilisons :
- Next, qui est un framework de React.
- Material UI, pour des composants React
- CSS, pour des styles particuliers
Pour l'environnement général, nous utilisons :
- Typescript, qui est transpilé en Javascript
- GraphQL, pour effectuer les requêtes
- Apollo Studio, pour les builds, gestion et optimisation des APIs GraphQL
- Jest pour les tests unitaires
- Cypress pour les tests end-to-end
- Git et Github, pour le versionnement et l’hébergement du code
- Docker et Dockerhub, pour les images à déployer et l’hébergement des images
- Visual Studio Code, pour l'édition du code
Déploiement
Le code Notre groupe ayant choisi d’avoir un dépôt par module, nous hébergeons sur github le code source dans une organisation commune avec :
- Un dépôt pour le back-end
- Un dépôt pour le front-end, dépendant du back, avec un docker-compose.yml
Le build Nous utilisons github actions, pour effectuer à chaque mise à jour du code back ou front :
- les tests de la base de code
- la fabrication de l’image docker
- la publication de cette image dans notre groupe sur dockerhub
Le déploiement Nous avons mis en place un service webhook, déclenchant via http, pour staging ou production :
- la récupération de la dernière image docker publiée sur dockerhub
- la mise en place locale sur le serveur de cette nouvelle image téléchargée
Le serveur étant une machine virtuelle mise à disposition temporairement par notre école.
\newpage
Gestion de projet
Présentation du groupe Oros
Notre formateur nous a proposé plusieurs sujets pendant notre alternance à la Wild Code School. Mon groupe et moi avons fait le choix de travailler un sujet de location, où il fallait développer un site qui met en relation des internautes avec un magasin de location, l’idée étant de faire un site pour un magasin qui fait des locations saisonnières pour les sports de montagne. Pour nous le cœur du sujet était la simplicité, pour rendre la location des biens le plus facile possible.
Notre application permet aux visiteurs de parcourir le catalogue et voir ce que le magasin a de disponible pour louer. Si un visiteur veut faire une réservation de matériel, il est obligé de créer un compte. Une fois le compte créé, il peut confirmer la disponibilité des produits, ajouter des produits dans son panier, puis en retirer ou modifier si besoin. Une fois décidé, il peut consulter un récapitulatif de son panier, puis créer une réservation pour les produits sélectionnés et finaliser la réservation par paiement. Pour le magasin, le rôle d’administrateur existe en plus du client. Seul un administrateur peut créer des nouveaux produits, en supprimer ou modifier si besoin, ainsi que consulter toutes les réservations en cours. Un utilisateur ne peut accéder à la partie administrative, mais un administrateur a accès à toutes les rubriques du site.
Organisation du groupe et méthodes
Pour notre projet, nous avons fait le choix d’utiliser la méthode AGILE. Nous avons fait une liste des fonctionnalités sur notre Trello partagé, et avons découpé les parties ainsi : Backlog (à faire), en cours (branche perso), prêt à déployer (dev), et on prod (main).
De cette façon, à tout moment, on pouvait voir qui travaillait sur quoi, et sur quelle branche de notre dépôt git. Nos branches git suivaient alors cette logique :
- main : code testé et prêt pour être déployé sur dockerhub
- dev : code fini qui doit être testé et intégré
- branche perso (nommé selon la fonctionnalité) : code qui est en cours
En plus de Git, nous avons utilisé Github, une plateforme collaborative pour développer des logiciels et héberger du code.
Afin de communiquer d’une manière fluide, en plus du Trello, nous avons eu à notre disposition un salon discord privé. Le serveur qui en faisait partie était accessible seulement aux personnes qui suivaient la formation, ayant été créé par le formateur de notre alternance. Comme notre salon était accessible seulement par ces personnes là, on a pu avoir l’esprit tranquille concernant nos communications ainsi que la confidentialité, car personne ne pouvait accéder à nos discussions. Nous avons aussi créé un Google Drive afin de centraliser les informations du projet.
Pour tous nos modèles, nous avons travaillé ensemble sur Miro dans un board commun afin que tout le monde puisse discuter et faire des modifications si besoin.
Pour la conception de nos wireframes ainsi que les maquettes de l’application, nous avons utilisé Figma.
\newpage
Les spécifications techniques du projet
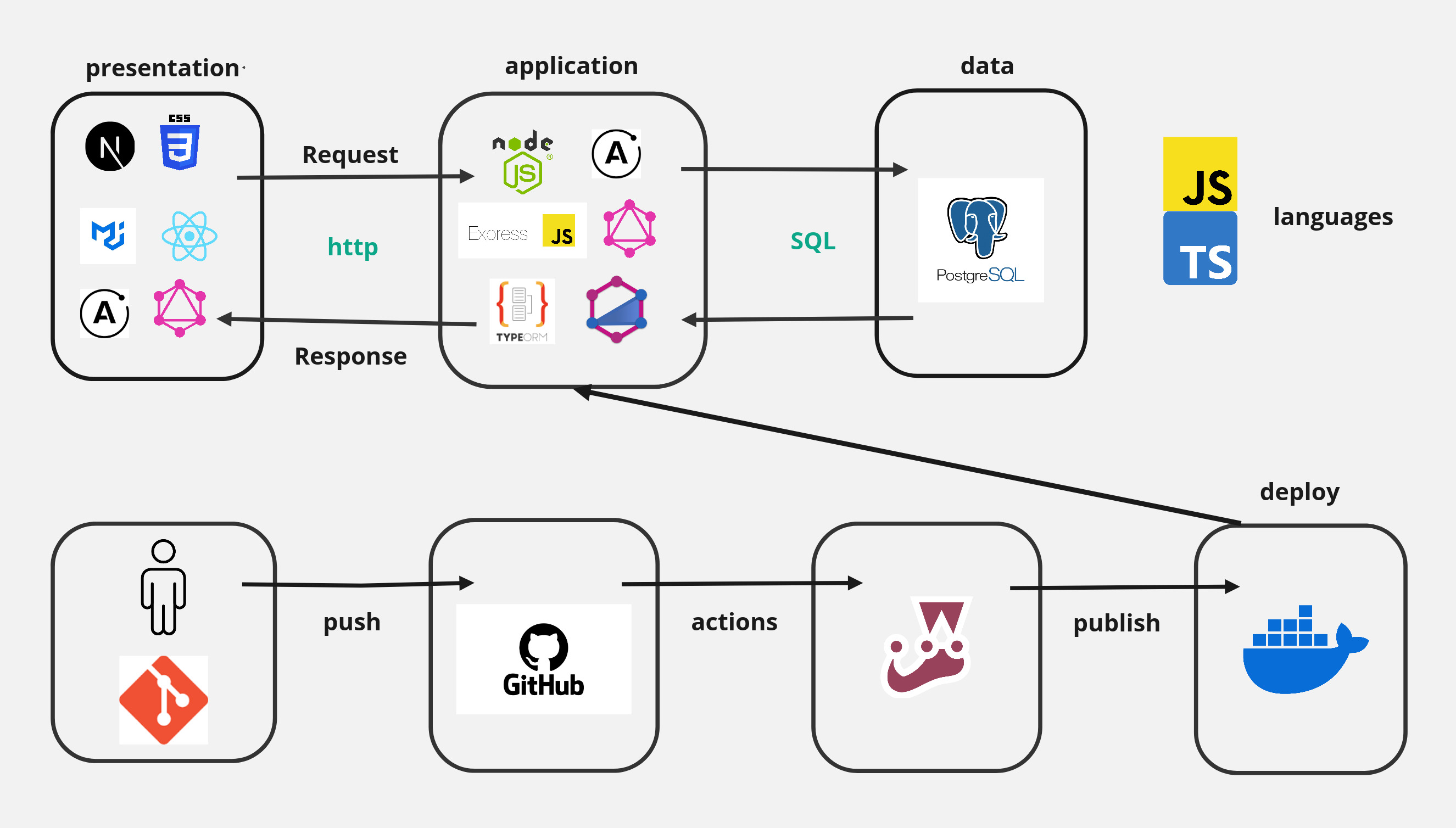
L'architecture du projet
 {width=70%}
{width=70%}
Technologies utilisées
Le Back-end :
- NodeJs : Un environnement bas niveau qui permet l’exécution du code JavaScript côté serveur. Comme il a un fonctionnement non bloquant, il permet de concevoir des applications en réseau performantes.
- ExpressJs : Un framework pour construire des applications web basées sur NodeJs. C’est pratique pour le développpement du serveur. Il permet une création d’API simple er robuste.
- TypeORM : Une bibliothèque ORM (Object-Relational Mapping) pour TypeScript/JavaScript qui permet d’interagir avec des bases de données relationnelles en utilisant des principes OOP (object-oriented programming). Elle permet une façon de gérer les connexions de base de données et définir les modèles (entités) qui représente les tables de base de données, facilitant le travail d’enregistrements de base de données comme objets.
- TypeGraphQL : Une bibliothèque qui construit des APIs GraphQL en utilisant TypeScript. Elle utilise les décorateurs et les classes pour définir les schémas GraphQL. Par exemple, on utilise le décorateur @ObjectType pour définir une classe comme un type GraphQL, et @Field pour déclarer les propriétés de cette classe qui seront mappées aux champs GraphQL. Type-GraphQL rend la création de requêtes, de mutations et de champs plus simple en les définissant comme des méthodes de classe classiques, à l’image des contrôleurs REST. Cela permet une distinction nette entre la logique métier et la couche de transport, tout en facilitant les tests unitaires des résolveurs, qui peuvent être considérés comme de simples services.
- PostgreSQL : Un système de gestion de base de données relationnelle orienté objet, qui dispose également de clés étrangères pour rélier les données entre plusieurs tables.
Le Front-end :
- NextJs : Un framework qui utilise la bibliothèque React et s’appuie sur la technologie NodeJs. Il est utilisé surtout pour réduire la charge sur les navigateurs web et fournir une sécurité accrue.
- Material UI : Une bibliothèque de composants React qui est basée sur du CSS. Elle permet une personnalisation profonde grâce à une large gamme de paramètres de styles et d’options de personnalisation.
- CSS : Un langage de style utilisé pour décrire la présentation du HTML.
L'Environnement Général :
- Typescript : Un langage qui ajoute un typage statique à Javascript, ce qui permet la définition des types de données pour les variables, les fonctions, et les objets.
- GraphQL : Un langage de requête de données pour API ainsi qu’un environnement d’exécution. Il permet aux clients de demander uniquement les données dont ils ont besoin. Contrairement aux APIs REST, GraphQL organise les requêtes de manière à obtenir des données provenant de plusieurs sources en un seul appel API. Côté serveur, il s’appuie sur un schéma qui décrit les données accessibles et utilise des résolveurs pour générer les valeurs correspondant aux requêtes. Côté client, il s'appuie sur deux opérations principales : les Queries et les Mutations. Les Queries permettent de lire les données (l'équivalent de "Read" dans le modèle CRUD), alors que les Mutations permettent de créer, modifier, ou supprimer des données, qui sont quant à elles équivalentes aux opérations "Create", "Update", et "Delete" dans le modèle CRUD.
- Apollo Studio : Une plateforme de Apollo GraphQL qui aide les développeurs à concevoir, gérer, et optimiser leurs APIs GraphQL. Pour le front-end, il y a Apollo Client, et le back-end, Apollo Server. Utiliser des outils de la même équipe rend les chose plus lisibles.
- Jest : Un framework de test Javascript qui permet de créer des tests unitaires.
- Cypress : Un framework d’automatisation de tests basé sur Javascript, pour les tests end-to-end.
- Git : Un outil de versioning qui permet de développer les fonctionnalités sur des branches.
- Github : Une plateforme collaborative pour développer des logiciels et héberger du code, où l’on peut pousser le code versionné avec Git.
- Docker : Un logiciel open-source qui permet de conteneuriser des applications afin de faciliter leur déploiement.
- Dockerhub : Une plateforme pour héberger des images Docker.
- Visual Studio Code : Un éditeur de code open source développé par Microsoft.
\newpage
Conception du projet
La Merise
La première chose que nous avons fait, c’était de décider quel type de location nous avions envie de faire, et comment on voulait s’organiser. Comme mentionné ci-dessus, nous avons tout d’abord créé un dossier Google Drive pour centraliser toute information pertinente. Ensuite, nous avons créé un document brainstorming pour nos premières idées pour les technologies que nous pensions utiliser afin de pouvoir créer le projet nécessaire. Afin de travailler sur la Merise et les diagrammes, nous avons utilisé Miro, une plateforme de collaboration numérique qui permet entre autres de créer des diagrammes.
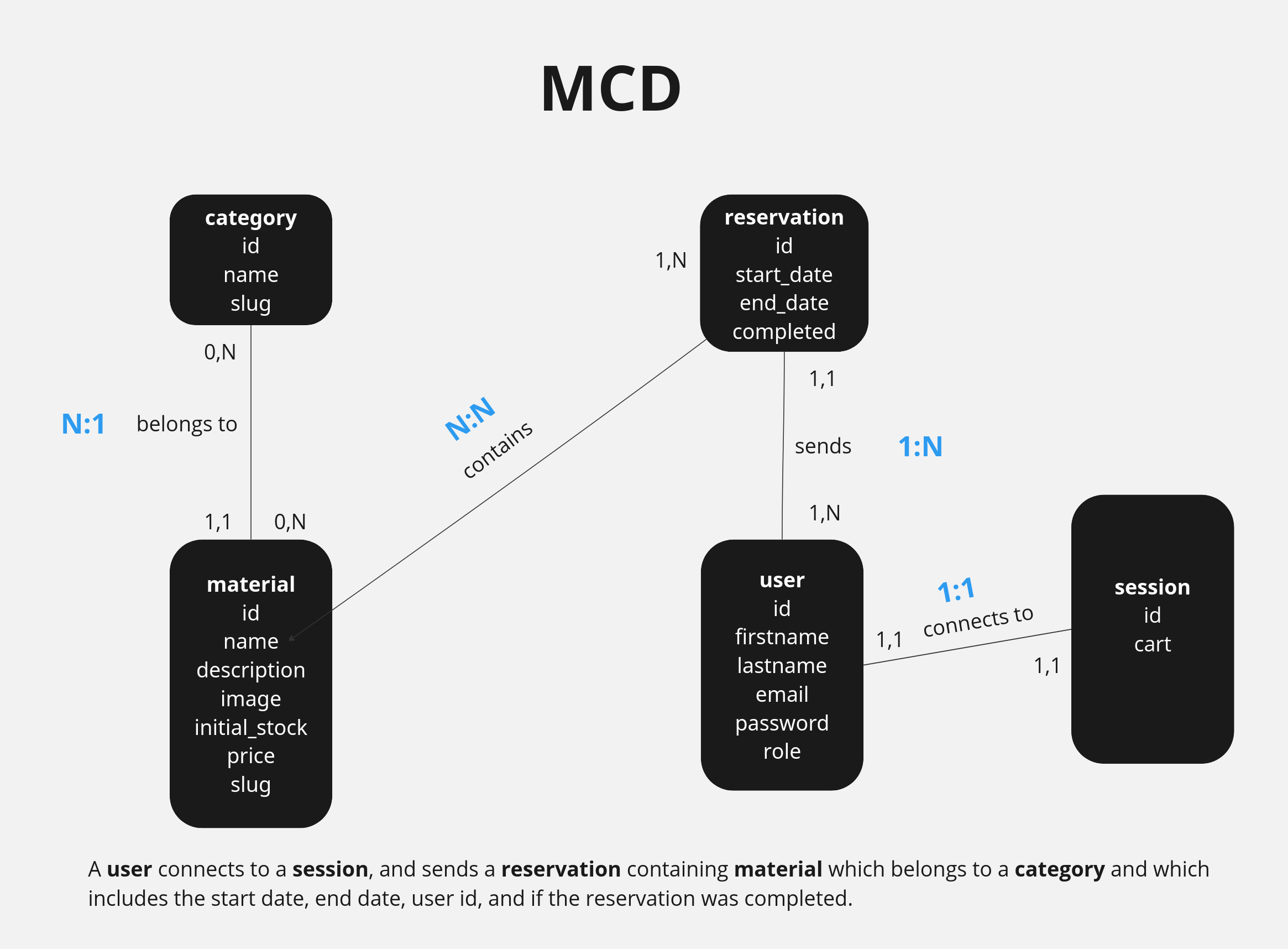
Modèle Conceptuel de Données
En faisant notre brainstorming, nous avons retenu ces éléments clés :
- Un utilisateur se connecte à une session.
- Un utilisateur fait au minimum une réservation mais peut en faire plusieurs.
- La réservation est faite par un utilisateur.
- La réservation contient au moins un matériel et au maximum plusieurs matériaux.
- Le matériel peut recevoir 0 réservations et au maximum plusieurs réservations.
- Chaque matériel appartient à une catégorie.
- Chaque catégorie peut contenir 0 matériels et au maximum plusieurs matériels.
Avec ceci, on a pu créer une phrase qui résume nos idées, et on peut créer le modèle conceptuel de données selon cette phrase :
Un utilisateur se connecte à une session, et envoie une réservation qui contient du matériel, et qui appartient à une catégorie, et elle contient la date de début, la date de fin, et si la réservation a été complétée.
 {width=70%}
{width=70%}
On a aussi fait les maximalités (chiffres en bleu dans notre diagramme). Cela nous a permis de voir rapidement que la relation entre réservation et material allait avoir un lien Many to Many, alors pour notre MLD, nous avons mis un tableau intermédiaire afin de mieux gérer ce lien.
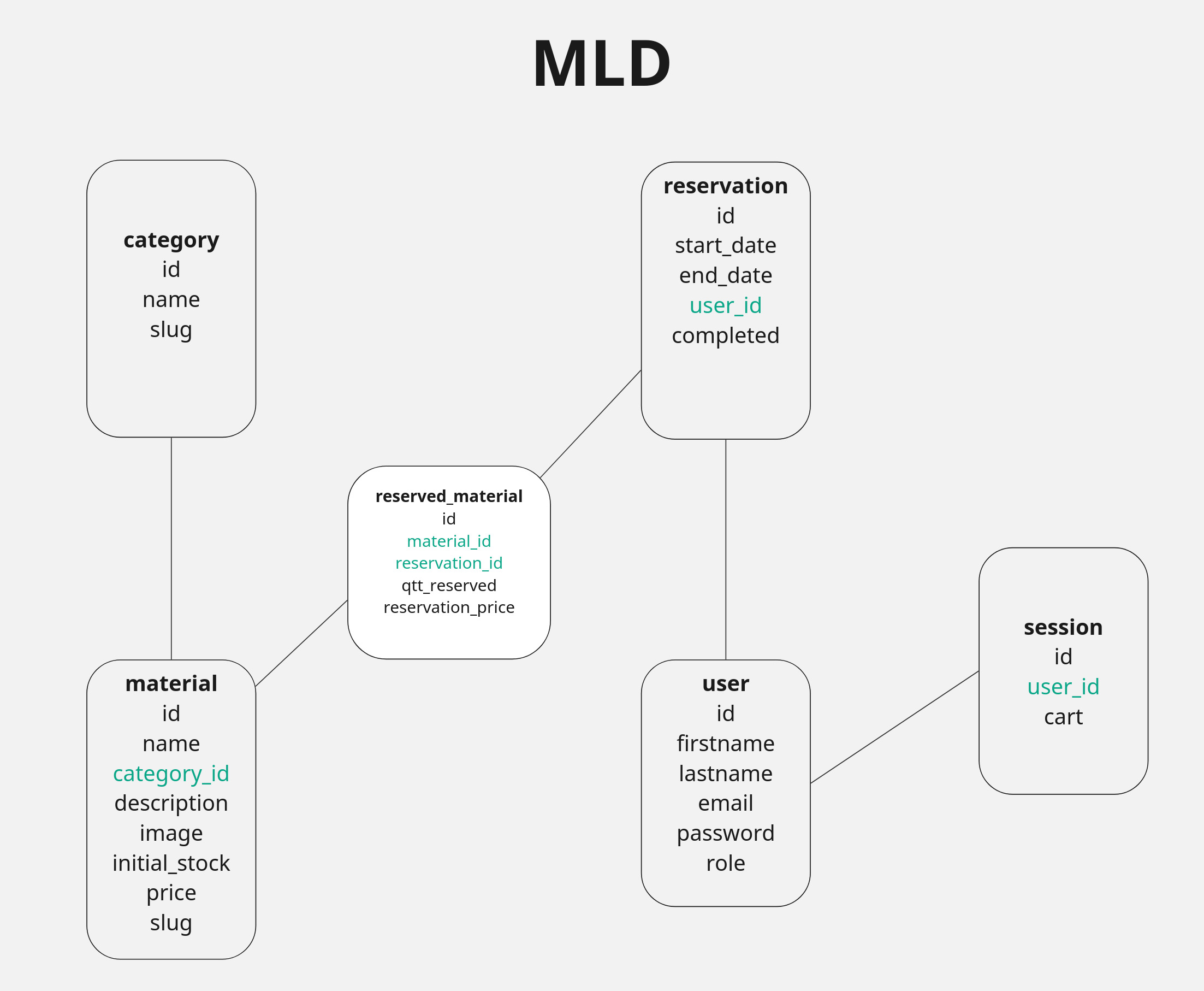
Modèle Logique de Données
Nous progressons vers le Modèle Logique de Données, une étape plus concrète dans la définition de la base de données. Comme mentionné ci-dessus, on peut voir qu'il est nécessaire de créer un tableau intermédiaire entre Réservation et Material, qu’on a décidé d’appeler reserved_material, afin d’éviter une relation Many to Many. À cause de cela, on voit qu’on a deux attributs qui sont des foreign keys dans ce tableau, alors que dans d’autres comme Reservation, on n'a qu'une seule clé étrangère pour lier les deux entités.
 {width=70%}
{width=70%}
\newpage
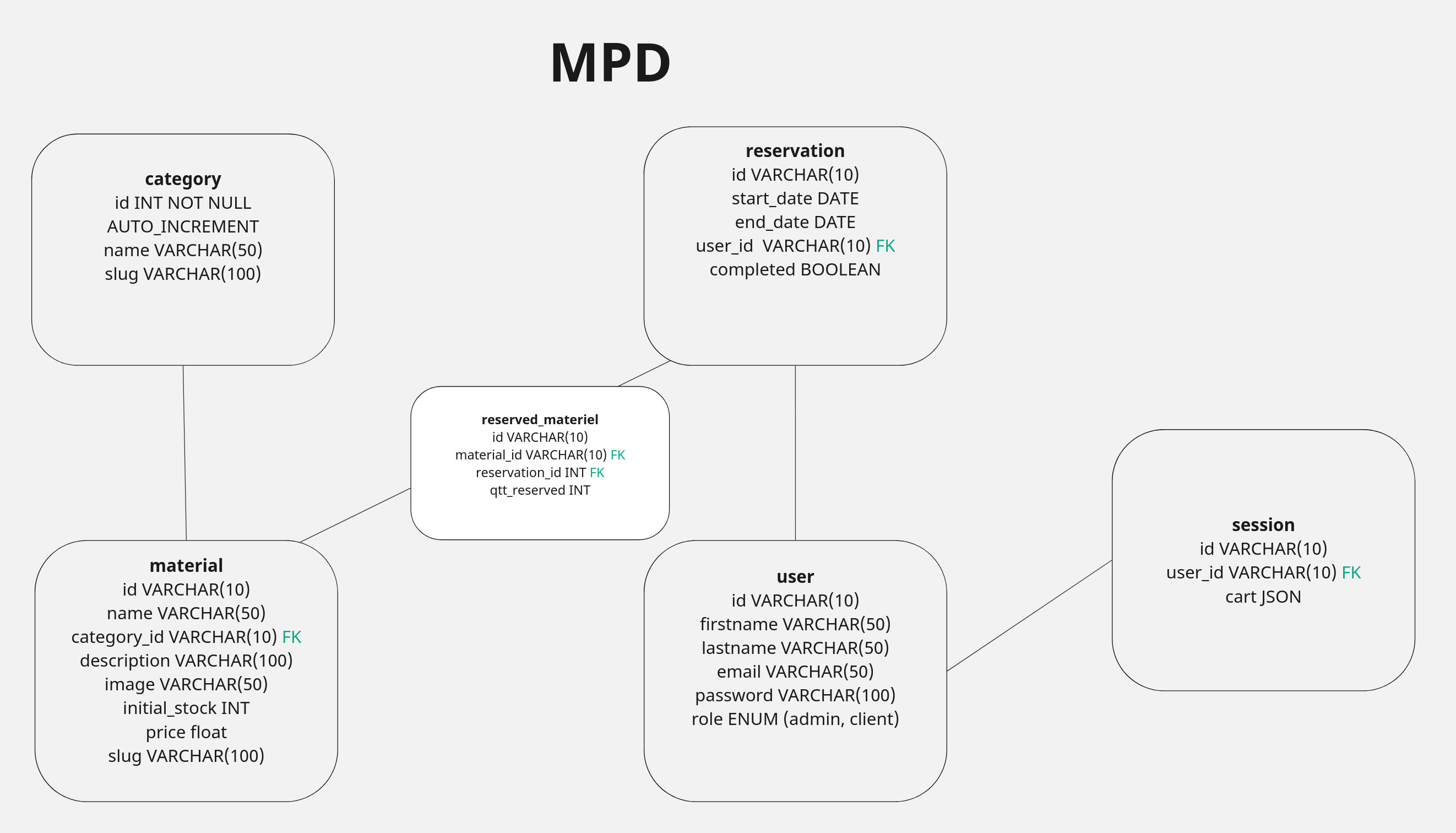
Modèle Physique de Données
Après avoir créé le modèle logique de données, nous avons procédé à créer le modèle physique de données. Cette étape est particulièrement importante car cela va nous aider à décider comment on va créer notre base de données. On peut déjà voir quels attributs sont les clés étrangères dans le MCD, comme ils sont en verts, mais on le précise également dans le MPD en mettant FK (foreign key) en vert.
 {width=70%}
{width=70%}
L’information vraiment pertinente dans le MPD qu’on ne trouve pas dans les autres modèles, c’est le type de données pour chaque objet. La plupart sont des VARCHAR, mais par exemple dans notre entité session, cart sera du JSON. Une autre chose qui change c’est que la plupart de nos ids sont du varchar, car on prévoit d’utiliser UUID, sauf dans le cas de l’id de catégorie, où nous avons prévu de faire de simples entiers qui vont s’auto incrémenter.
\newpage
Unified Modeling Language
Après la création de notre merise, nous avons continué à travailler avec la création de l’UML, ou Unified Modeling Language. Le premier modèle que nous avons travaillé, c’était le diagramme de classes. Vous trouverez le diagramme de classes complet dans l’annexe.
Diagramme de classe
Le diagramme de classe reflète la définition des classes transformées en entités via GraphQL, les services, et les méthodes intégrées avec TypeORM, ainsi que les entrées pour les interactions avec le front-end.
Pour le diagramme de classes, nous nous reposons sur ces idées :
- Nous cherchons à développer un système qui gère la location des matériels à notre magasin.
- Ce magasin contient des matériels.
- Un matériel est caracterisé par son nom, sa description, son image, son stock initial, son prix.
- Un matériel est attribué à au moins une catégorie, qui a son nom.
- Pour louer un matériel, un utilisateur doit créer un compte sur le site, avec son prénom, nom de famille, son email et un mot de passe.
- Chaque fois qu'un utilisateur se connecte à notre site, cela crée une session, où nous pouvons garder les informations de leur panier dans un fichier JSON.
\newpage
Multiplicités
Dans le diagramme de classes, il faut travailler les multiplicités, alors si on prend l’exemple de l’entité User, dans les deux directions, vers Reservation ainsi que Session, on voit qu’il y a une Multiplicité de 1. Pourquoi ? Car un User est relié à une session. Il ne peut en avoir plusieurs. Une Reservation est également reliée à seulement un User, alors c’est également 1.
{height=50%}
\newpage
Portée
On peut avoir plusieurs types de portées pour les attributs : public, privé, ou protégé par exemple. On a décidé de garder tout public à part les mots de passe pour un utilisateur, qui sont privés, pour des raisons de sécurité. De cette façon, les autres classes ne pourront pas y accéder, et cela protège ces données.
En plus de montrer les liens entre chaque Entity, on a également pris le temps d’imaginer à quoi ressemblent nos services. En prenant User comme exemple encore, on voit comment on a décidé de créer UserService, ainsi qu’un type InputRegister, afin d’éviter de répéter les mêmes informations.
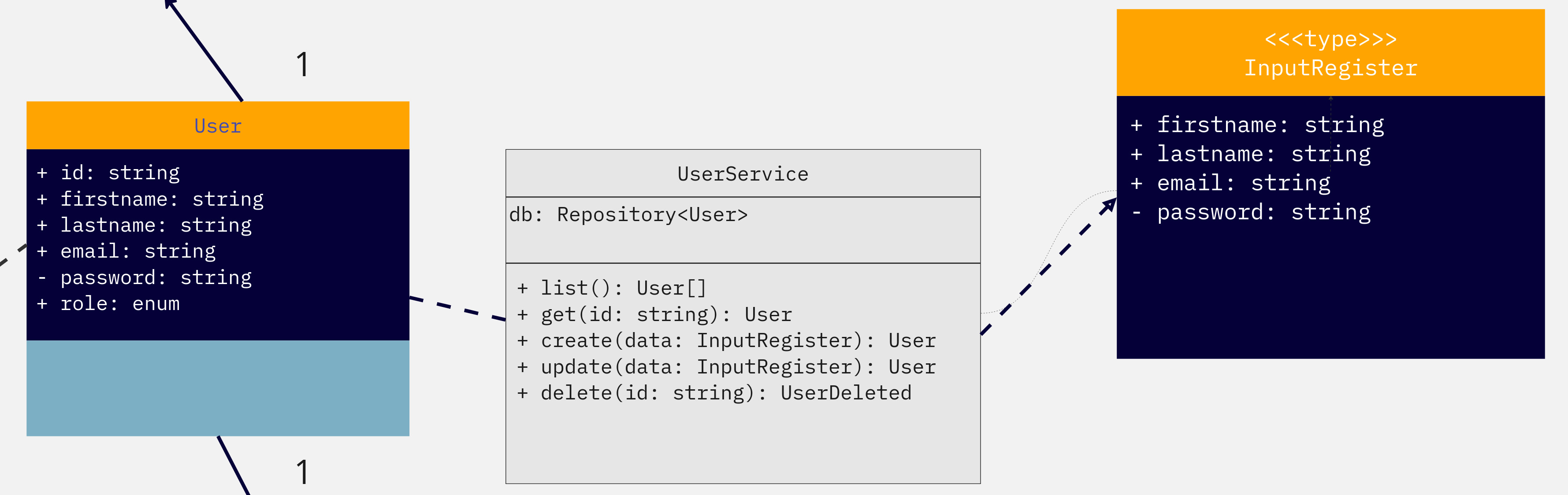
En utilisant un exemple de notre code, on voit bien que dans notre UserService, on a pu faire la création de User plus simplement en suivant ce que nous avons prévu de faire dans notre diagramme de classes :
// User.entity.ts -- InputType
@InputType()
export class InputRegister {
@Field()
@Column()
firstname: string;
@Field()
@Column()
lastname: string;
@Field()
@Column({ unique: true })
email: string;
@Field()
@Column()
password: string;
}
// création de User dans user.services.ts
async create(data: InputRegister) {
const newUser = await this.db.create(data);
return await this.db.save(newUser);
}
Diagramme de cas d'utilisation
Afin de clarifier la fonctionnalité de notre site par rapport aux visiteurs, nous avons procédé à un diagramme de cas d’utilisation. Cette étape a été primordiale, car ça nous a permis de décider comment procéder avec la création de compte, le login, et le panier. On a décidé qu’un simple visiteur pourrait regarder le catalogue, mais s’il veut procéder à une réservation, il faut créer un compte et se logger. Alors, seulement un client qui s’est loggé pourrait avoir accès au panier.
Un admin, cependant, a des droits qu’un client n’a pas. Il peut créer, mettre à jour, et supprimer des matériels si nécessaire.
{width=60%}
\newpage
Diagramme de séquence
Le dernier diagramme UML que nous avons créé était un diagramme de séquence. Nous avons choisi de se concentrer sur comment réagit un client loggé sur le site. On peut voir que quand le client fait une requête de l’inventaire du site, il devrait recevoir une réponse avec les résultats de cette recherche. Il pourrait ensuite regarder la description du matériel ainsi que l’ajouter dans son panier, et puis enfin procéder au paiement si désiré.
{width=60%}
\newpage
Maquettes et enchaînement des maquettes
Suite à une séance de brainstorming sur notre vision de l'application, en tenant compte des éléments fournis par le client dans le cahier des charges, et après avoir travaillé la Merise et nos diagrammes, nous avons commencé à créer un wireframe avec l'outil Figma. Ce wireframe nous offre une représentation schématique et simplifiée de l'application, nous permettant de visualiser rapidement sa structure, son arborescence ainsi que l'organisation des composants et des interactions. Cela constitue une base solide pour débuter l'élaboration de la maquette.

Ensuite, nous avons créé un moodboard pour définir l'orientation design du site. Nous avons réfléchi à l'expérience utilisateur (UX) et à l'interface utilisateur (UI) afin d'assurer une expérience à la fois efficace, agréable et fonctionnelle, tout en répondant aux attentes du client. Les maquettes intègrent des éléments visuels tels que les couleurs, les typographies, les icônes et les images, afin de représenter le style et l'identité visuelle de l'application. Nous avons également inclus des éléments d'interaction comme des boutons et des formulaires pour illustrer les fonctionnalités de l'application. Les maquettes finales ont servi de référence visuelle tout au long du processus de développement, facilitant ainsi la communication entre les différentes parties prenantes du projet. Le travail de maquettage sur Figma a été crucial pour la planification et la réalisation du projet, car il a permis de visualiser et de valider le concept avant sa mise en œuvre.


\newpage
Le Projet
Création et connexion à la base de données et accès aux données
Une fois que la modélisation et les maquettes ont été faites, nous avons créé notre base de données avec PostgreSQL, décrite dans les étapes suivantes :
Configuration de TypeORM
Nous avons mis en place TypeORM en établissant les paramètres de connexion à la base de données dans un fichier de configuration. Ce dernier inclut des détails tels que le type de base de données (PostgreSQL), l’hôte, le port, l’utilisateur, le mot de passe, et précise également les entités impliquées dans le projet (voir point suivant) :
// datasource.ts
import { DataSource } from 'typeorm';
import Material from '../entities/Material.entity';
import User from '../entities/User.entity';
import Reservation from '../entities/Reservation.entity';
import Category from '../entities/Category.entity';
import ReservedMaterial from '../entities/ReservedMaterial.entity';
import Session from '../entities/Session.entity';
export default new DataSource({
type: 'postgres',
host: 'db',
port: 5432,
database: process.env.POSTGRES_DB,
username: process.env.POSTGRES_USER,
password: process.env.POSTGRES_PASSWORD,
entities: [Material, User, Reservation, Category, ReservedMaterial, Session],
});
Définition des Entités avec TypeORM et TypeGraphQL
Nous avons fait les entités pour modéliser les tables de la base de données. Chaque entité est créée sous forme de classe, utilisant des décorateurs TypeORM pour indiquer les colonnes, les types de données et les relations entre les entités, ainsi que des décorateurs TypeGraphQL pour rendre ces entités accessibles via l'API GraphQL. Par exemple, l'entité Category représente la table des catégories dans la base de données. Le décorateur @ObjectType permet de déclarer la classe comme un type GraphQL, tandis que @PrimaryGeneratedColumn et @Column spécifient les colonnes de la base de données. Le décorateur @OneToMany indique la relation entre les entités Category et Material. Des types d'entrée sont également créés pour faciliter la création et la mise à jour des catégories par le biais de mutations GraphQL.
import { Field, ID, ObjectType, InputType } from 'type-graphql';
import { Column, Entity, OneToMany, PrimaryGeneratedColumn } from 'typeorm';
import Material from './Material.entity';
@ObjectType()
@Entity()
class Category {
@Field(() => ID)
@PrimaryGeneratedColumn()
id: number;
@Field()
@Column()
name: string;
@Field(() => [Material], { nullable: true })
@OneToMany(() => Material, (m) => m.category, { nullable: true })
materials: Material[];
@Field()
@Column()
slug: string;
}
@InputType()
export class InputCreateCategory {
@Field()
name: string;
@Field()
slug: string;
}
@InputType()
export class InputUpdateCategory {
@Field()
@PrimaryGeneratedColumn('uuid')
id: string;
@Field({ nullable: true })
name: string;
@Field({ nullable: true })
slug: string;
}
@ObjectType()
export class CategoryDeleted {
@Field()
name: string;
@Field()
slug: string;
}
export default Category;
Opérations CRUD avec TypeORM
Les opérations de création, lecture, mise à jour et suppression de données s'effectuent dans les services grâce aux méthodes fournies par TypeORM. Cela permet une gestion efficace des données dans PostgreSQL tout en maintenant la logique métier distincte de l’implémentation des requêtes.
Prenons le service CategoryServices, qui s'occupe de l'entité Category. Ce service utilise TypeORM pour communiquer avec la base de données PostgreSQL, en offrant des méthodes telles que la création (create), la lecture (findById et list), la mise à jour (update) et la suppression (delete) d'une catégorie. De plus, le service est conçu pour gérer les relations entre les catégories et les matériaux associés, en utilisant des décorateurs TypeORM comme @OneToMany.
Ci-dessous un exemple des méthodes CRUD pour l’entité Category, dans CategoryService :
// category.service.ts
import { Repository } from 'typeorm';
import {
InputCreateCategory,
InputUpdateCategory,
} from '../entities/Category.entity';
import datasource from '../lib/datasource';
import Category from '../entities/Category.entity';
class CategoryServices {
db: Repository<Category>;
constructor() {
this.db = datasource.getRepository(Category);
}
async list() {
return await this.db.find({ relations: { materials: true } });
}
async findById(id: number) {
const category = await this.db.findOne({
where: { id },
relations: { materials: true },
});
if (!category) {
throw new Error("La catégorie n'existe pas");
}
return category;
}
async create(data: InputCreateCategory) {
const newCategory = await this.db.create(data);
return await this.db.save(newCategory);
}
async update(id: number, data: Omit<InputUpdateCategory, 'id'>) {
const findCategory = await this.db.findOne({
where: { id },
});
if (findCategory) {
const materialToSave = this.db.merge(findCategory, { ...data });
return await this.db.save(materialToSave);
}
}
async delete(id: number) {
const categoryToDelete = await this.db.findOne({
where: { id },
});
console.log('categoryToDelete', categoryToDelete);
if (!categoryToDelete) {
throw new Error("Le matériel n'existe pas!");
}
return await this.db.remove(categoryToDelete);
}
}
export default CategoryServices;
Dans ce contexte, TypeORM facilite la gestion des données de manière efficace grâce à des méthodes telles que find, findOne, create, save, merge et remove. Cela permet d'exécuter les opérations CRUD de façon fluide et harmonieuse avec les entités définies, tout en tenant compte des relations entre les tables.
Intégration avec GraphQL et Apollo
Pour finir, TypeORM est associé à GraphQL et Apollo Server, ce qui simplifie les opérations de requêtage et de mutation sur la base de données. Les resolvers GraphQL interviennent sur le serveur pour gérer ces actions. Ils permettent d’accéder aux entités définies par TypeORM pour les requêtes (queries) et de manipuler les données lors des mutations (création, mise à jour et suppression). Chaque résolveur correspond à une opération particulière de l'API GraphQL, garantissant ainsi une communication fluide entre le front-end et le back-end.
Par exemple, le résolveur dédié à la gestion des catégories inclut des requêtes telles que createCategory pour créer une catégorie et updateCategory pour en mettre une à jour en fonction de son identifiant. On peut voir avec le code ci-dessous qu'il suit les besoins d’une méthode CRUD, selon les méthodes fournies par CategoryServices.
// category.resolver.ts
import { Arg, Authorized, Mutation, Query, Resolver } from 'type-graphql';
import {
InputCreateCategory,
InputUpdateCategory,
} from '../entities/Category.entity';
import CategoryServices from '../services/category.service';
import Category from '../entities/Category.entity';
@Resolver()
export default class CategoryResolver {
@Query(() => [Category])
async listCategories() {
const category: Category[] = await new CategoryServices().list();
return category;
}
@Query(() => Category)
async findCategoryById(@Arg('id') id: string) {
const categories: Category = await new CategoryServices().findById(+id);
return categories;
}
@Authorized('ADMIN')
@Mutation(() => Category)
async createCategory(@Arg('infos') infos: InputCreateCategory) {
const result: Category = await new CategoryServices().create(infos);
console.log('RESULT', result);
return result;
}
@Authorized('ADMIN')
@Mutation(() => Category)
async updateCategory(@Arg('infos') infos: InputUpdateCategory) {
const { id, ...otherData } = infos;
const categoryToUpdate = await new CategoryServices().update(
+id,
otherData,
);
return categoryToUpdate;
}
@Authorized('ADMIN')
@Mutation(() => Category)
async deleteCategory(@Arg('id') id: string) {
const categories: Category = await new CategoryServices().delete(+id);
return categories;
}
}
\newpage
Authentification
L'authentification au sein de l'application repose sur plusieurs méthodes de sécurité cruciales, telles que le hachage des mots de passe, l'emploi de JWT (JSON Web Token), la gestion des cookies et la création d'un contexte utilisateur.
Hachage des mots de passe
Les mots de passe des utilisateurs sont protégés grâce à la bibliothèque argon2, qui est utilisée pour les hacher avant leur enregistrement dans la base de données. Le processus de hachage s'effectue via des middleware TypeORM, comme @BeforeInsert et @BeforeUpdate, qui déclenchent le hachage à chaque fois qu'un mot de passe est ajouté ou modifié. Ainsi, même si la base de données venait à être compromise, les mots de passe resteraient inaccessibles.
// User.entity.ts
type ROLE = 'ADMIN' | 'CLIENT';
@ObjectType()
@Entity()
export default class User {
@BeforeInsert()
@BeforeUpdate()
protected async hashPassword() {
if (!this.password.startsWith('$argon2')) {
this.password = await argon2.hash(this.password);
}
}
Plus d'informations concernant argon2 dans la section Sécurité.
JWT et gestion des cookies
Les JSON Web Tokens (JWT) servent à authentifier les utilisateurs lors de leur connexion et tout au long de leur session. Après la validation du mot de passe via argon2, un JWT est créé avec la bibliothèque jose. Ce token inclut des informations non sensibles, comme l’adresse email et le rôle de l’utilisateur, qui sont intégrées dans le payload du JWT. Cela permet d’éviter de vérifier le rôle en base de données à chaque requête, ce qui allège la charge du serveur.
Un JWT est composé de trois éléments : l’en-tête, le payload et la signature. L’en-tête, fourni automatiquement par la bibliothèque jose, indique l’algorithme de chiffrement utilisé (dans notre cas, HS256). La signature est générée en combinant l’en-tête, le payload et une clé secrète (process.env.SECRET_KEY). Cette clé est cruciale pour la sécurité du JWT, car elle assure que le token n’a pas été modifié. Elle doit rester strictement confidentielle et ne jamais être divulguée.
Le JWT est ensuite enregistré dans un cookie HTTP-only, ce qui empêche l'accès par des scripts JavaScript malveillants, protégeant ainsi l'application contre les attaques XSS (Cross-Site Scripting). Grâce à ce cookie, l'utilisateur demeure authentifié pour chaque requête HTTP, et si un token valide est détecté, les informations qu'il renferme (comme l'email et le rôle) sont extraites pour établir le contexte de l'utilisateur.
Les JWT fonctionnent en mode "stateless", ce qui signifie que les informations de session ne sont pas conservées sur le serveur. Cela présente l'avantage de ne pas occuper de mémoire serveur pour la gestion des sessions, facilitant ainsi une authentification fluide dans une architecture de microservices. En utilisant une clé secrète partagée entre plusieurs applications, un seul token peut être utilisé pour s'authentifier sur différents services, éliminant le besoin de recréer une session utilisateur pour chaque service.
De plus, une date d’expiration est intégrée au JWT grâce à la méthode .setExpirationTime(), limitant ainsi sa validité à 2 heures dans notre cas.
index.ts
export interface Payload {
email: string;
}
// user.resolver.ts
@Query(() => Message)
async login(@Arg('infos') infos: InputLogin, @Ctx() ctx: MyContext) {
const user = await new UserServices().findUserByEmail(infos.email);
if (!user) {
throw new Error('Vérifiez votre information de login');
}
const isPasswordValid = await argon2.verify(user.password, infos.password);
const m = new Message();
if (isPasswordValid) {
const token = await new SignJWT({ email: user.email, role: user.role })
.setProtectedHeader({ alg: 'HS256', typ: 'jwt' })
.setExpirationTime('2h')
.sign(new TextEncoder().encode(`${process.env.SECRET_KEY}`));
const cookies = new Cookies(ctx.req, ctx.res);
cookies.set('token', token, { httpOnly: true });
// Créer ou récupérer la session
const sessionServices = new SessionServices();
const session = await sessionServices.createOrGetSession(ctx, user);
m.message = 'Welcome!';
m.success = true;
} else {
m.message = 'Vérifiez votre information de login';
m.success = false;
}
return m;
}
@Query(() => Message)
async logout(@Ctx() ctx: MyContext) {
if (ctx.user) {
const cookies = new Cookies(ctx.req, ctx.res);
}
const m = new Message();
m.message = 'Vous avez été déconnecté';
m.success = true;
return m;
}
Contexte de l’utilisateur
Le contexte utilisateur est créé dans le middleware Express, où le JWT est récupéré des cookies, vérifié, et l'utilisateur associé est extrait de la base de données. Ce contexte est ensuite disponible dans les résolveurs GraphQL, ce qui permet de limiter l'accès à certaines ressources ou d'adapter les réponses en fonction de l'utilisateur connecté.
//index.ts
export interface MyContext {
req: express.Request;
res: express.Response;
user: User | null;
}
//index.ts
expressMiddleware(server, {
context: async ({ req, res }) => {
let user: User | null = null;
const cookies = new Cookies(req, res);
const token = cookies.get('token');
console.log('Token from cookies:', token); // Log du token récupéré
if (token) {
try {
const verify = await jwtVerify<Payload>(
token,
new TextEncoder().encode(process.env.SECRET_KEY),
);
// Log du payload du token
console.log('Token verified:', verify.payload);
user = await new UserService().findUserByEmail(
verify.payload.email,
);
console.log('User found:', user); // Log de l'utilisateur récupéré
} catch (err) {
console.log('Error verifying token:', err);
}
} else {
console.log('No token found in cookies');
}
return { req, res, user };
},
}),
Autorisation avec TypeGraphQL
De plus, pour renforcer la sécurité, nous avons mis en place un système d'authentification et de gestion des autorisations utilisant le décorateur @Authorized de TypeGraphQL et un customAuthChecker. Ce dispositif permet de protéger les résolveurs et de contrôler l'accès aux différentes fonctionnalités de l'application selon les rôles des utilisateurs.
Le décorateur @Authorized est employé pour limiter l'accès à certains résolveurs ou champs. Par exemple, nous avons appliqué @Authorized("ADMIN") sur des résolveurs sensibles, tels que la création, la modification ou la suppression de catégorie (voir pages 25 et 26), afin que seuls les administrateurs puissent y accéder. Pour d'autres cas, nous avons opté pour @Authorized("USER", "ADMIN"), permettant ainsi l'accès aux utilisateurs et aux administrateurs. Lorsque qu'un résolveur n'exige pas de restrictions particulières, mais qu'il doit vérifier que l'utilisateur est authentifié, nous utilisons @Authorized() pour s'assurer que l'accès est réservé aux utilisateurs connectés.
// authChecker.ts
import { AuthChecker } from "type-graphql";
import { MyContext } from "..";
export const customAuthChecker: AuthChecker<MyContext> = (
{ context },
roles
) => {
if (context.user) {
// si l 'utilisateur est connecté
// vérifier que le user a le role demandé
// si le tableau de roles a une longueur > 1
if (roles.length > 0) { // si un role est indiqué au décorateur
//et que le user a le role parmi ce tableau
if (roles.includes(context.user.role)) {
return true; //on laisse passer
} else { //sinon
return false; //on bloque
}
}
//si le user est connecté et qu'on a pas spécifié de rôle, on laisse passer
return true;
}
//si le user n'est pas connecté quand on utilise le décorateur, on bloque
return false;
};
// index.ts
import { customAuthChecker } from './lib/authChecker';
export interface MyContext {
req: express.Request;
res: express.Response;
user: User | null;
}
export interface Payload {
email: string;
}
const app = express();
const httpServer = http.createServer(app);
async function main() {
const schema = await buildSchema({
resolvers: [
MaterialResolver,
UserResolver,
ReservationResolver,
CategoryResolver,
ReservedMaterialResolver,
SessionResolver
],
validate: false,
authChecker: customAuthChecker,
});
CORS (Cross-Origin Resource Sharing)
Pour sécuriser les échanges entre le client et le serveur, les paramètres CORS sont configurés de manière à limiter l'origine des requêtes à une liste prédéfinie de domaines de confiance. Cela garantit que seules les applications autorisées peuvent interagir avec l'API.
app.use(
'/',
cors<cors.CorsRequest>({
origin: [
'http://localhost:3000',
'http://localhost:4005',
'https://studio.apollographql.com',
'https://1123-jaune-1.wns.wilders.dev/',
'https://staging.1123-jaune-1.wns.wilders.dev/',
],
credentials: true,
}),
\newpage
Front-end
La configuration
Pour créer le front-end de l’application avec NextJs, nous avons créé trois fichiers principaux : index.tsx, _app.tsx, et _document.tsx.
- Dans le fichier index.tsx, nous avons configuré la page d'accueil de notre application en important et en utilisant le composant HomepageContent, qui renferme le contenu principal de la page sur laquelle l'utilisateur sera dirigé à son entrée dans l'application.
// index.tsx
import HomepageContent from "@/components/HomepageContent/HomepageContent";
export default function Home() {
return (
<main>
<div>
<HomepageContent />
</div>
</main>
);
}
- Le fichier index.tsx est intégré dans le composant App, défini dans _app.tsx, qui s'occupe de la configuration générale de l'application. Dans _app.tsx, nous avons mis en place un client Apollo pour gérer les requêtes GraphQL et avons utilisé AppCacheProvider afin d'optimiser les performances des composants Material-UI. Nous avons également désactivé le rendu côté serveur (SSR) pour cette application. De plus, nous avons ajouté le composant MainNav dans _app.tsx pour garantir que la navigation principale soit accessible sur toutes les pages, tout en permettant de déterminer si l'on se trouve sur la page d'accueil, ce qui nous aidera à adapter la navigation selon les besoins.
// src/pages/_app.tsx
import type { AppProps } from "next/app";
import { ApolloClient, InMemoryCache, ApolloProvider } from "@apollo/client";
import { AppCacheProvider } from "@mui/material-nextjs/v13-pagesRouter";
import dynamic from "next/dynamic";
import { ThemeProvider } from "@mui/material/styles";
import CssBaseline from "@mui/material/CssBaseline";
import MainNav from "@/components/MainNav/MainNav";
import Footer from "@/components/Footer/Footer";
import { useRouter } from "next/router";
import theme from "@/theme"; // Import du thème personnalisé
import AuthProvider from "@/context/authProvider";
export const client = new ApolloClient({
uri: "http://localhost:4005/",
cache: new InMemoryCache({
addTypename: false,
}),
credentials: "include",
});
function App({ Component, pageProps, ...props }: AppProps) {
const router = useRouter();
return (
<>
<AppCacheProvider {...props}>
<ApolloProvider client={client}>
<ThemeProvider theme={theme}>
<CssBaseline />
<AuthProvider>
<div className="app-container">
<MainNav />
<main className="main-content">
<Component {...pageProps} />
</main>
<Footer />
</div>
</AuthProvider>
</ThemeProvider>
</ApolloProvider>
</AppCacheProvider>
</>
);
}
// Disabling SSR
export default dynamic(() => Promise.resolve(App), { ssr: false });
- Enfin, dans le fichier
_document.tsx, nous avons modifié le document HTML produit par NextJs en ajoutant les balises requises pour Material-UI dans la section<head>du document.
// _document.tsx
import { Html, Head, Main, NextScript } from "next/document";
import {
DocumentHeadTags,
documentGetInitialProps,
DocumentHeadTagsProps,
} from '@mui/material-nextjs/v13-pagesRouter';
export default function Document(props: DocumentHeadTagsProps) {
return (
<Html lang="en">
<Head>
<DocumentHeadTags {...props} />
</Head>
<body>
<Main />
<NextScript />
</body>
</Html>
);
}
Document.getInitialProps = async (ctx: any) => {
const finalProps = await documentGetInitialProps(ctx);
return finalProps;
};
Apollo client et GraphQL Codegen
Nous avons utilisé Apollo Client et GraphQL Codegen pour simplifier et optimiser la gestion des données entre le front-end et notre API GraphQL.
- Apollo Client est une bibliothèque qui facilite la communication avec le serveur GraphQL. Elle simplifie l'envoi des requêtes et des mutations, tout en intégrant les états de chargement, de réussite et d'erreur directement au sein de nos composants.
- GraphQL Codegen, de son côté, génère automatiquement des types TypeScript et des hooks à partir de nos schémas GraphQL, ce qui assure une fiabilité du typage, diminuant ainsi les erreurs et augmentant la productivité.
Tout d'abord, nous établissons nos requêtes et nos mutations dans des fichiers spécifiques, qui servent de fondation pour Apollo Client et Codegen, comme illustré ici :
// requests/queries/auth.queries.ts
import { gql } from "@apollo/client";
export const LOGIN = gql`
query Login($infos: InputLogin!) {
login(infos: $infos) {
success
message
}
}
`;
export const LOGOUT = gql`
query Logout {
logout {
success
message
}
}
`;
// requests/queries/categories.queries.ts
import { gql } from "@apollo/client";
export const LIST_CATEGORIES = gql`
query ListCategories {
listCategories {
id
name
slug
}
}
`;
export const FIND_CATEGORY = gql`
query FindCategoryById($id: String!) {
findCategoryById(id: $id) {
id
materials {
id
name
price
image
slug
}
}
}
`;
Ensuite, nous configurons Codegen pour qu'il utilise à la fois nos schémas disponibles sur le serveur et les requêtes et mutations définies dans nos fichiers .queries.ts et .mutation.ts.
Codegen produit alors un fichier qui contient les types et les hooks correspondants.
Prenons, par exemple, le composant Login pour la connexion et MainNav pour la navigation.
Login.tsx
Ici, nous utilisons le hook useLazyQuery avec la requête LOGIN (définie dans notre fichier auth.queries.ts) pour authentifier les utilisateurs. Lors de la soumission du formulaire, useLazyQuery déclenche la requête avec les informations d'identification (email et mot de passe) et renvoie la réponse du serveur. Cela nous permet de gérer l'état d'authentification de manière asynchrone, affichant des messages de succès ou d'erreur selon la réponse reçue. Contrairement à useQuery, qui exécute la requête dès que le composant est monté, useLazyQuery attend une action explicite, comme la soumission du formulaire.
// login.tsx
import { Box, Button, TextField, Typography } from '@mui/material';
import { useLazyQuery } from '@apollo/client';
import { useState } from 'react';
import { LOGIN } from '@/requests/queries/auth.queries';
import { redirect } from 'next/navigation';
import useAuth from '@/hooks/useAuth';
import { client } from '../_app';
import { useRouter } from 'next/router'
interface LoginProps {
showRegister: () => void;
closeModals: () => void;
}
const Login: React.FC<LoginProps> = ({ showRegister, closeModals }) => {
const router = useRouter()
const getUserInfos = useAuth();
console.log("currentUser", getUserInfos);
const [formState, setFormState] = useState({
email: '',
password: '',
});
const [loginUser, { data, loading, error }] = useLazyQuery(LOGIN, {
onCompleted: async (data) => {
console.log("Mutation complété:", data);
if (data.login.success) {
closeModals();
await client.refetchQueries({include:["UserInfos"]});
router.push('/');
}
},
onError: (error) => {
console.error("Erreur de mutation:", error);
},
});
const handleChange = (e: React.ChangeEvent<HTMLInputElement>) => {
const { name, value } = e.target;
setFormState({
...formState,
[name]: value,
});
};
const handleSubmit = async (e: React.FormEvent) => {
e.preventDefault();
try {
const response = await loginUser({
variables: {
infos: {
email: formState.email,
password: formState.password,
},
},
});
console.log("Réponse du serveur:", response);
} catch (e) {
console.error("Erreur de soumission:", e);
}
};
MainNav.tsx
Dans ce composant, nous faisons appel à des hooks générés par GraphQL-Codegen, comme useListCategoriesQuery et useListMaterialsQuery, pour récupérer les données relatives aux catégories et aux matériels. Ces hooks sont créés automatiquement à partir de nos schémas et requêtes GraphQL, ce qui garantit un typage TypeScript rigoureux et une intégration fluide avec Apollo Client. Grâce à ces hooks, nous pouvons aisément obtenir et afficher la liste des matériels dans le champ de recherche ainsi que les catégories sous forme de boutons de navigation dynamiques, permettant ainsi à notre application de gérer les données de manière efficace.
// MainNav.tsx
const {
loading: loadingMaterial,
error: errorMaterial,
data: dataMaterial,
} = useListMaterialsQuery({
fetchPolicy: "no-cache",
});
const {
loading: loadingCategories,
error: errorCategories,
data: dataCategories,
} = useListCategoriesQuery({
fetchPolicy: "no-cache",
});
if (loadingMaterial || loadingCategories) return <p>Loading...</p>;
if (errorMaterial || errorCategories) return <p>Error loading data.</p>;
//variable pour itérer sur les matériels et les afficher dans l'autocomplete
const materials =
dataMaterial?.listMaterials?.map((material) => ({
label: material.name,
id: material.id,
})) || [];
Dans cette navigation principale, nous modifions dynamiquement l'interface en fonction de la page où se trouve l'utilisateur. Un état local isHomePage (de type booléen) ainsi que isAdminRoute (aussi un booléen) sont établis selon le pathname fourni par le routeur. Le hook useEffect surveille les changements de route et met à jour cet état en conséquence. Cela nous permet d'afficher ou de masquer les boutons selon quel type d'utilisateur se trouve sur la page d'accueil, en utilisant les données récupérées.
// MainNav.tsx
const [isHomePage, setIsHomePage] = useState<boolean>(true);
// Hook pour définir si on est sur la page d'accueil et mettre à jour le state
useEffect(() => {
setIsHomePage(router.pathname === "/");
}, [router]);
// MainNav.tsx
{isHomePage && !isAdminRoute && (
<>
<div>
<Typography className={styles.title}>
Louez le matériel adapté à votre sport de montagne !
</Typography>
</div>
<div className={styles.categoryButtonsRow}>
<ul>
{dataCategories?.listCategories?.map((category: Category) => (
<li key={category.id} className={styles.categoryButtonList}>
<CategoryButton name={category.name} id={category.id} />
</li>
))}
</ul>
</div>
Accueil

Catégorie "Sports d'hiver"

Lorsque l'utilisateur se trouve sur la page d'accueil, ces boutons de catégorie sont visibles, offrant un accès direct aux différentes catégories de matériels. Ces boutons sont créés dynamiquement en parcourant les catégories obtenues grâce à la requête GraphQL. Chaque bouton permet de rediriger l'utilisateur vers une page de liste de matériels correspondant à la catégorie choisie.
Le fichier categories/[id].tsx dans Next.js utilise le routage dynamique pour afficher les détails d'une catégorie spécifique. Le segment [id] dans l'URL permet de capturer l'identifiant de la catégorie et de le transmettre comme paramètre à la page. Cette dernière effectue une requête GraphQL pour récupérer les matériels liés à la catégorie sélectionnée et les affiche dans une liste. Chaque matériel est rendu à l'aide d'un composant MaterialCard, qui présente les informations détaillées sur le matériel.
// categories/[id].tsx
import MaterialCard from "@/components/MaterialCard/MaterialCard";
import { useFindCategoryByIdQuery } from "@/types/graphql";
import { useRouter } from "next/router";
import React, { useState } from "react";
import { Grid, Pagination } from "@mui/material";
const CategoryPage = () => {
const router = useRouter();
const { id } = router.query;
const { loading, error, data } = useFindCategoryByIdQuery({
variables: { id: id as string },
skip: !id,
});
const itemsPerPage = 4;
const [currentPage, setCurrentPage] = useState(1);
if (loading) return <p>Loading...</p>;
if (error) return <p>Error: {error.message}</p>;
const materials = data?.findCategoryById?.materials || [];
const startIndex = (currentPage - 1) * itemsPerPage;
const endIndex = startIndex + itemsPerPage;
const currentMaterials = materials.slice(startIndex, endIndex);
const totalPages = Math.ceil(materials.length / itemsPerPage);
const handlePageChange = (
event: React.ChangeEvent<unknown>,
value: number
) => {
setCurrentPage(value);
};
return (
<div>
<h1
style={{
color: "black",
marginTop: "20px",
marginBottom: "20px",
paddingLeft: "15px",
}}
>
Nos produits
</h1>
<Grid
container
spacing={2}
style={{ paddingLeft: "16px", paddingRight: "16px" }}
>
{currentMaterials.map((material) => (
<Grid item xs={12} sm={6} md={3} key={material.id}>
<MaterialCard material={material} />
</Grid>
))}
</Grid>
<div
style={{
display: "flex",
justifyContent: "center",
marginTop: "20px",
marginBottom: "20px",
}}
>
<Pagination
count={totalPages}
page={currentPage}
onChange={handlePageChange}
color="primary"
/>
</div>
</div>
);
};
export default CategoryPage;
Les boutons de catégorie sont implémentés à l'aide d'un composant réutilisable CategoryButton, qui redirige l'utilisateur vers la page de la catégorie correspondante.
// CategoryButton.tsx
import { Button } from '@mui/material';
import React from 'react';
import styles from '../components/MainNav/MainNav.module.css';
function CategoryButton({name, id}: {name: string, id: string}) {
return (
<div>
<Button
className={styles.categoryButton}
variant="contained"
href={`/categories/${id}`}
style={{width: 285}}
>{name}</Button>
</div>
);
}
export default CategoryButton;
Material-UI
Material-UI (MUI) est une bibliothèque de composants React qui facilite la création d'interfaces utilisateur modernes et adaptatives. Basée sur les principes du Material Design de Google, MUI offre une vaste sélection de composants pré-stylisés, tels que des boutons, des champs de texte, des modales et des icônes, tout en permettant de personnaliser le thème pour s'adapter aux besoins particuliers de chaque projet. En simplifiant la conception d'interfaces cohérentes et accessibles, elle permet de réduire considérablement le temps de développement des éléments d'interface de qualité.
Dans notre projet, MUI est utilisé pour structurer et styliser diverses sections de l'application, comme par exemple le formulaire de connexion dans le fichier Login.tsx. Ces composants TextField et Button de MUI sont utilisés pour concevoir un formulaire d'authentification attrayant, tandis que le composant Box permet d'encadrer le tout avec des marges et un style harmonieux.
// login.tsx
return (
<Box sx=
{{
maxWidth: 500,
mx: 'auto',
mt: 4,
p: 2,
border: '1px solid #ccc',
borderRadius: 2,
backgroundColor:'white'
}}
>
<Typography
variant="h4"
style=
{{
color:'black',
textAlign:'center',
marginBottom:'2rem'
}}
>
Se connecter à votre compte
</Typography>
<form onSubmit={handleSubmit}>
<TextField
type="email"
name="email"
label="Email"
value={formState.email}
onChange={handleChange}
required
fullWidth
margin="normal"
/>
<TextField
type="password"
name="password"
label="Password"
value={formState.password}
onChange={handleChange}
required
fullWidth
margin="normal"
/>
<Button
type="submit"
variant="contained"
color="primary"
disabled={loading}
fullWidth style={{marginBottom:'2rem'}}
>
{loading ? 'Submitting...' : 'Login'}
</Button>
{error &&
<Typography
style={{color:'red',
textAlign:'center'}}
>
Aucun compte associé à cet email
</Typography>}
</form>
<Typography
onClick={showRegister}
style=
{{
color:'black',
textAlign:'center',
cursor: 'pointer'
}}
>Vous ne possédez pas de compte ? Inscrivez-vous
</Typography>
{data && data.login.success &&
<Typography
style=
{{
color:'green',
textAlign:'center'
}}
>
Success! {data.login.message}
</Typography>}
{data && !data.login.success &&
<Typography
style=
{{
color:'red',
textAlign:'center'
}}
>
Mot de passe incorrect
</Typography>}
</Box>
);
Le composant Box permet de créer un cadre esthétique et centré pour le formulaire, tandis que Typography est utilisé pour styliser le titre. Les composants MUI garantissent une apparence homogène tout en gérant automatiquement les interactions des utilisateurs, comme les états de chargement via le bouton Button.
Dans MainNav.tsx, des composants tels qu'Autocomplete, Box et Modal sont employés pour rendre la navigation intuitive et interactive. Par exemple, un champ de recherche pour les matériels et une modale pour la connexion sont mis en place.
// MainNav.tsx
{!isAdminRoute && (
<Autocomplete
disablePortal
id="combo-box-demo"
options={materials}
onChange={handleOptionSelect}
sx={{ width: 300 }}
className={styles.input}
renderInput={(params) => (
<TextField {...params} label="Rechercher un matériel" />
)}
/>
)}
// MainNav.tsx
<Modal
open={isModalOpen}
onClose={() => setIsModalOpen(false)}
aria-labelledby="modal-modal-title"
aria-describedby="modal-modal-description"
className={styles.modal}
style={{
display: "flex",
alignItems: "center",
justifyContent: "center",
border: "1px solid black",
}}
>
{showRegisterModal ? (
<Box>
<Register showRegister={openLoginModal} />
</Box>
) : (
<Box>
<Login
showRegister={openRegisterModal}
closeModals={closeAllModals}
/>
</Box>
)}
</Modal>
\newpage
Tests
Les tests jouent un rôle essentiel dans la maintenance et l'amélioration d'une application au fil du temps, en s'assurant que chaque nouvelle fonctionnalité ou modification n'entraîne pas de régressions ou de bugs. Ils se déclinent en plusieurs catégories, chacune ayant un objectif spécifique :
-
Tests unitaires : Ces tests portent sur une unité de code, souvent une seule fonction ou méthode. Leur but est de valider que chaque élément isolé de l'application fonctionne comme prévu. Les tests unitaires sont rapides à exécuter et ne nécessitent pas d'environnement complexe. Ils constituent la majorité des tests réalisés par les développeurs.
-
Tests d'intégration : Ces tests vérifient l'interaction entre plusieurs composants ou fonctions, permettant d'évaluer leur intégration dans un sous-ensemble de l'application. Par exemple, un test d'intégration peut garantir qu'un composant et son enfant interagissent correctement, offrant ainsi un équilibre entre les tests unitaires et les tests end-to-end.
-
Tests end-to-end (E2E) : Ces tests couvrent l'ensemble du flux d'une application en simulant les actions des utilisateurs. Ils évaluent l'application dans son intégralité, de l'interface à la base de données. Bien qu'ils soient plus lents et moins précis que les tests unitaires, car ils englobent une plus grande surface fonctionnelle, ils sont précieux pour vérifier que l'application fonctionne correctement dans des scénarios réels.
Dans notre projet Oros, nous avons ajouté jest, une bibliothèque de tests pour les applications JavaScript, développée par Facebook. Pour écrire un test, il est nécessaire de suivre certaines règles de nommage pour les fichiers, comme Jest ne comprend que des fichiers basés sur TypeScript ou JavaScript.
Nous avons procédé ainsi avec les tests :
Test back-end
Le test suivant simule la réponse du serveur à une requête listMaterials en utilisant un mock store pour reproduire le comportement de la base de données. Cela nous permet de tester la requête sans avoir besoin d'une base de données réelle ou du back-end.
// __tests__/material.test.ts
import assert from 'assert';
import {
IMockStore,
addMocksToSchema,
createMockStore,
} from '@graphql-tools/mock';
import { ApolloServer } from '@apollo/server';
import { buildSchemaSync } from 'type-graphql';
import { printSchema } from 'graphql';
import { makeExecutableSchema } from '@graphql-tools/schema';
import MaterialResolver from '../src/resolvers/material.resolver';
import Material from '../src/entities/Material.entity';
const materialsData: Material[] = [
{
id: '1',
name: 'My Material 1',
category: {
id: 1,
name: 'Category 1',
materials: [],
slug: 'category-1',
},
description: 'Description 1',
image: 'image1.jpg',
initial_stock: 10,
price: 10.5,
slug: 'my-material-1',
},
{
id: '2',
name: 'My Material 2',
category: {
id: 2,
name: 'Category 2',
materials: [],
slug: 'category-2',
},
description: 'Description 2',
image: 'image2.jpg',
initial_stock: 20,
price: 20.5,
slug: 'my-material-2',
},
];
Dans ce test, nous établissons une requête LIST_MATERIALS pour interroger notre API et obtenir une liste de matériaux. Nous simulons cette liste avec des données fictives stockées dans un mock store. Ce store est généré à l'aide de createMockStore, grâce à la bibliothèque @graphql-tools/mock, qui permet de simuler une base de données en mémoire.
// __tests__/material.test.ts
export const LIST_MATERIALS = `#graphql
query ListMaterials {
listMaterials {
id
}
}
`;
type ResponseData = {
material: Material[];
};
let server: ApolloServer;
const baseSchema = buildSchemaSync({
resolvers: [MaterialResolver],
authChecker: () => true,
});
const schemaString = printSchema(baseSchema);
const schema = makeExecutableSchema({ typeDefs: schemaString });
const resolvers = (store: IMockStore) => ({
//resolvers est une fonction qui reçoit le store en argument!
Query: {
listMaterials() {
return store.get('Query', 'ROOT', 'listMaterials');
},
},
});
beforeAll(async () => {
const store = createMockStore({ schema });
server = new ApolloServer({
schema: addMocksToSchema({
schema: baseSchema,
store,
resolvers,
}),
});
store.set('Query', 'ROOT', 'listMaterials', materialsData);
});
Le mock store conserve des objets de données, tels que les matériaux, que les résolveurs GraphQL peuvent interroger. Dans ce cas, listMaterials est configuré pour récupérer les matériels depuis le store, plutôt que depuis une base de données réelle. Cela nous permet de simuler la logique de récupération des données sans nécessiter un environnement de back-end complet. Le serveur Apollo est configuré pour utiliser un schéma GraphQL et des résolveurs fictifs via @graphql-tools/mock, qui fournissent les données du store.
Ce test vérifie ensuite que la réponse de l'API contient bien les identifiants des matériels attendus, confirmant ainsi le bon fonctionnement de la requête listMaterials. Ce type de tests d'intégration assure que les résolveurs et le schéma GraphQL interagissent correctement avec la logique du store.
// __tests__/material.test.ts
describe('Test sur les matériels', () => {
it('Récupération des matériels depuis le store', async () => {
const response = await server.executeOperation<ResponseData>({
query: LIST_MATERIALS,
});
assert(response.body.kind === 'single');
expect(response.body.singleResult.data).toEqual({
listMaterials: [{ id: '1' }, { id: '2' }],
});
});
});
\newpage
Tests front-end
Tests front-end : Pour ce qui concerne le front, nous avons mis en place deux tests sur notre Main Nav, un test unitaire ainsi qu'un test d'intégration. Mais tout d’abord, comme il y a un import d’un fichier css dans notre nav bar (MainNav.tsx), il fallait trouver un moyen de contourner cela, car comme mentionné ci-dessus, jest ne reconnaît que des fichiers ts ou tsx.
Pour éviter ce problème, nous avons installé webpack, un module bundler qui permet de traiter différents types de fichiers. Dans notre cas, il est particulièrement utile pour transformer la compréhension des fichiers css pour Jest. Nous avons aussi ajouté une ligne de code supplémentaire dans notre jest.config.ts pour rediriger et rendre compréhensible le css existant dans notre MainNav.
// jest.config.ts
// resolution for @ aliases
moduleNameMapper: {
'^@/(.*)$': '<rootDir>/src/$1',
'\\.(css|less)$': '<rootDir>/__mocks__/styleMock.js',
},
Et par conséquent, nous avons créé ce fichier vide pour la redirection :
//styleMock.js
module.exports = {};
En plus de ce contournement du fichier CSS, nous avons aussi mis en place un MockedProvider, car chaque test d'un composant React qui utilise Apollo Client doit être disponible dans le contexte de React. Dans le code de l'application, on crée ce contexte en encapsulant les composants, alors pour imiter au mieux ce schéma, on utilise MockedProvider.
Pour le premier test (un test unitaire), on teste si notre fichier MainNav.tsx affiche bien notre titre ; en utilisant la méthode findByText, qui peut retourner un élément trouvé dans le DOM ou lancer une erreur si aucun élément correspondant n'est trouvé, ainsi que toBeInTheDocument comme une manière supplémentaire de s'assurer que l'élement existe dans le DOM au moment du test.
// Navbar.test.tsx
// test sur le titre
jest.mock("next/router", () => ({
useRouter: jest.fn().mockReturnValue({
pathname: "/",
}),
}));
describe("MainNav", () => {
it("rendu du titre dans la navbar", async () => {
render(
<MockedProvider
mocks={[
{
request: {
query: LIST_MATERIALS,
},
result: {
data: {
listMaterials: [],
},
},
},
{
request: {
query: LIST_CATEGORIES,
},
result: {
data: {
listCategories: [],
},
},
},
]}
>
<MainNav />
</MockedProvider>
);
const titre = await screen.findByText(
"Louez le matériel adapté à votre sport de montagne !"
);
expect(titre).toBeInTheDocument();
});
Pour le deuxième test (un test d'intégration), on veut s'assurer qu'un des boutons (nous avons choisi le bouton stock) apparaît lorqu'on est connecté en tant qu'admin sur notre application. Comme c'est un bouton qui apparaît seulement lorsqu'on est connecté en tant qu'admin, cela nous assure que l'intéraction entre le login et le MainNav fonctionne correctement. Pour ce faire, on crée un mock user contenant les infos nécessaires dans USER_INFOS.
// Navbar.test.tsx
// test sur l'apparition du bouton stock lors d'être connecté comme admin
it("mock d'un faux utilisateur connecté", async () => {
render(
<MockedProvider
mocks={[
{
request: {
query: LIST_MATERIALS,
},
result: {
data: {
listMaterials: [],
},
},
},
{
request: {
query: LIST_CATEGORIES,
},
result: {
data: {
listCategories: [],
},
},
},
{
request: {
query: USER_INFOS,
},
result: {
data: {
userInfos: {
id: "123",
firstname: "admin",
lastname: "adminer",
email: "test@myoros.com",
role: "ADMIN",
},
},
},
},
]}
>
<AuthProvider>
<MainNav />
</AuthProvider>
</MockedProvider>
);
const adminLink = await screen.findByTestId("admin-link");
expect(adminLink).toBeInTheDocument();
});
Comme on teste notre bouton en utilisant findByTestId; ce test id doit également apparaître dans notre MainNav afin que ce test fonctionne correctement :
{width=70%}
\newpage
Intégration continue (CI) et déploiement continu (CD)
Pour faciliter le déploiement et réduire les interventions manuelles, nous avons instauré un système d'intégration et de déploiement continu (CI/CD) tant en pré-production qu'en production. Ce système utilise divers outils, notamment GitHub Actions, des webhooks, Docker, DockerHub, et Caddy en tant que proxy inverse.
- Github Actions : Introduit en 2019, GitHub Actions est une solution CI/CD qui s'intègre directement aux dépôts GitHub. Elle permet d'activer des workflows en fonction d'événements, tels qu'un push sur une branche. Dans le cadre de mon projet, j'ai mis en place deux workflows YAML pour :
- lancer des tests automatiquement
- envoyer des images Docker à Dockerhub
- Docker & Dockerhub : Les workflows de GitHub Actions créent des images Docker, qui sont ensuite sauvegardées sur DockerHub, un registre en ligne pour les images Docker. DockerHub facilite la gestion des images Docker en proposant des outils pour les créer, les tester, les stocker et les déployer.
- Caddy : Nous avons choisi Caddy comme proxy inverse pour gérer les requêtes HTTP vers notre domaine. Un proxy inverse est un serveur logiciel qui redirige les requêtes entrantes vers d'autres serveurs et renvoie ensuite la réponse au client. Ce dispositif permet de répartir la charge entre les serveurs et d'améliorer la sécurité.
En plus de sa fonction de redirection, Caddy facilite la gestion du protocole HTTPS (HyperText Transfer Protocol Secure). HTTPS assure la confidentialité et l'intégrité des données échangées entre le client et le serveur grâce au protocole Transport Layer Security (TLS), qui remplace l'ancien SSL. Ce protocole offre trois niveaux essentiels de protection :- Chiffrement des données pour éviter leur interception
- Intégrité des données pour garantir qu'elles ne sont pas altérées
- Authentification pour vérifier l'identité du serveur en communication
- Webhooks : Enfin, les webhooks sont configurés pour exécuter des scripts sur le serveur lorsque se produit un événement particulier, comme une mise à jour de branche. Cela permet d'automatiser des actions telles que le déploiement ou la mise à jour d'une application, sans nécessiter d'intervention manuelle.
Nous avons donc mis en place des workflows d'intégration continue (CI) afin d'automatiser les tests et le déploiement Docker de nos applications front-end et back-end. Ces workflows s'activent à chaque push, garantissant ainsi que le code est systématiquement testé et que les images Docker sont construites et publiées en cas de réussite des tests. En suivant la documentation officielle pour la configuration des workflows, le fichier YAML doit être placé dans le répertoire projet .github/workflows.
Workflow Back-end
Le workflow back-end est divisé en deux étapes principales :
- Tests Jest : Lorsqu'un push est effectué, les tests du back-end sont lancés grâce au script
npm run test-ci. Ces tests vérifient le bon fonctionnement des différentes sections de l'application, s'assurant que les modifications apportées au code ne causent pas de régressions. - Build et Push Docker : Si les tests réussissent sur la branche main, une image Docker de l'application back-end est créée et envoyée sur DockerHub. Les secrets GitHub sont employés pour protéger les identifiants de DockerHub.
// .github/workflows/back.tests.yml
name: jest-and-docker-ci
on: push
jobs:
test-back:
runs-on: ubuntu-latest
steps:
- name: Check out code
uses: actions/checkout@v2
- name: run tests
run: npm i && npm run test-ci
docker:
needs: test-back
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- name: Set up QEMU
uses: docker/setup-qemu-action@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Login to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v4
with:
push: true
context: '{{defaultContext}}'
tags: ${{ secrets.DOCKERHUB_USERNAME }}/wns-jaune-oros-back:latest
Workflow Front-end
Le workflow front-end suit la même structure que le back-end :
// .github/workflows/front-tests.yml
name: jest-and-docker-ci
on: push
jobs:
test-front:
runs-on: ubuntu-latest
steps:
- name: Check out code
uses: actions/checkout@v2
- name: run tests
run: npm i && npm run test-ci
docker:
needs: test-front
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- name: Set up QEMU
uses: docker/setup-qemu-action@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Login to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v4
with:
push: true
context: "{{defaultContext}}"
tags: ${{ secrets.DOCKERHUB_USERNAME }}/wns-jaune-oros-front:latest
Ensuite, nous avons mis en place l'environnement serveur requis pour le déploiement continu, en supposant que le VPS, Docker et Docker Compose ont déjà été installés au préalable.
- Organisation des dossiers : Nous avons créé deux dossiers, staging et production, dans le répertoire principal de notre projet Oros sur le VPS. Chaque dossier renferme plusieurs fichiers de configuration essentiels :
-
Docker-compose-prod.yml : Ce fichier indique à Docker comment construire et lancer les services du back-end, du front-end, et de la base de données. Il précise la version des services afin d'assurer des déploiements stables et reproductibles. Ce fichier est destiné à la production (prod), contrairement à docker-compose-staging.yml, qui est utilisé uniquement en phase de développement.
-
Nginx.conf : Ce fichier gère la redirection des requêtes /graphql vers notre application Node.js et sert également les fichiers statiques en transmettant les informations à Caddy.
-
fetch-and-deploy-${{ENV}}.sh : Ce script bash, appelé par la configuration de notre Webhook, redémarre les services via Docker Compose avec les dernières versions des images Docker. Il spécifie également les ports utilisés par Nginx (8000 pour la production et 8001 pour le staging), ce qui permet à Caddy de rediriger correctement les requêtes.
-
.env : Ce fichier contient les variables d'environnement nécessaires au projet, telles que les secrets utilisés par les services. Il est lu par docker-compose-prod.yml pour fournir ces informations aux conteneurs Docker.
-
Configuration de Caddy et des webhooks : Nous avons aussi écrit les fichiers de configuration pour Caddy et les webhooks :
-
Caddyfile : Ce fichier permet de rediriger les requêtes entrantes grâce à la directive reverse_proxy vers les ports appropriés. Les requêtes adressées à staging.1123-jaune-1.wns.wilders.dev sont redirigées vers le port 8001 (staging), celles destinées à 1123-jaune-1.wns.wilders.dev vont vers le port 8000 (production), tandis que les requêtes à ops.1123-jaune-1.wns.wilders.dev sont redirigées vers le port 9000 (service Webhook).
-
Webhook.conf : Ce fichier de configuration au format JSON spécifie les actions à réaliser lors de la réception d'une notification. Nous avons configuré deux webhooks :
- update-staging : le premier est déclenché automatiquement par Dockerhub lorqu'une nouvelle image est disponible, comme nous avons fait un lien entre les deux :
 {width=70%}
{width=70%}- update-prod : le deuxième peut être lancé en allant à
https://ops.1123-jaune-1.wns.wilders.dev/hooks/update-produne fois que les résultats surhttps://staging.1123-jaune-1.wns.wilders.devont été vérifé afin de mettre en place l'image la plus récente de Dockerhub
-
Fichiers Docker Compose et Nginx : Voici un aperçu des fichiers utilisés pour la configuration de nos services et de notre proxy :
- services : backend, frontend, db, nginx : Le fichier docker-compose-staging.yml configure les services du back-end (Node.js), du front-end (Next), de la base de données (Postgres), ainsi qu’Nginx pour gérer le proxy inverse. Chacun de ces services est surveillé par Docker, avec des vérifications de santé (healthcheck) et des dépendances clairement établies entre eux.
// wns_student@wns-project-server:~/apps/oros/staging$ services: backend: image: orosgroup/wns-jaune-oros-back expose: - 4000 env_file: - ./db.env healthcheck: test: - CMD-SHELL - > curl -f http://backend:4000/graphql?query=%7B__typename%7D -H 'Apollo-Require-Preflight: true' || exit 1 interval: 10s timeout: 30s retries: 5 depends_on: db: condition: service_healthy frontend: image: orosgroup/wns-jaune-oros-front expose: - 3000 depends_on: backend: condition: service_healthy env_file: - ./.env db: image: postgres restart: always env_file: - ./db.env expose: - 5432 healthcheck: test: ["CMD-SHELL", "pg_isready -d oros -U utilisateur"] interval: 10s timeout: 5s retries: 5 volumes: - orosdatabase:/var/lib/postgresql/data nginx: image: nginx:1.21.3 depends_on: - backend - frontend restart: always ports: - ${GATEWAY_PORT:-8001}:80 volumes: - ./nginx.conf:/etc/nginx/nginx.conf - ./logs:/var/log/nginx adminer: image: adminer restart: always ports: - 8087:8080- nginx.conf : Ce fichier a pour rôle de rediriger les requêtes entrantes. Par exemple, les requêtes adressées à /graphql sont redirigées vers le back-end, tandis que toutes les autres sont envoyées vers le front-end.
// nginx.conf events {} http { include mime.types; server { listen 80; location /graphql { proxy_pass http://backend:4000; } } }- fetch-and-deploy.sh : Ce script bash automatise le processus de redéploiement en arrêtant les services en cours, récupérant les dernières versions des images Docker, puis redémarrant les services sur le port approprié.
#!/bin/sh # fetch-and-deploy.sh docker compose -f docker-compose-prod.yml down && \ docker compose -f docker-compose-prod.yml pull && \ GATEWAY_PORT=8000 docker compose -f docker-compose-prod.yml up -d;- Caddyfile et webhook.conf : Ces fichiers s'occupent respectivement des redirections vers les ports adéquats et de l'automatisation du redéploiement à travers les webhooks.
# Caddyfile 1123-jaune-1.wns.wilders.dev { # Redirect request to production running on port 8000 reverse_proxy localhost:8000 # log log { output file /var/log/caddy/production.log } } staging.1123-jaune-1.wns.wilders.dev { # Redirect request to staging running on port 8001 reverse_proxy localhost:8001 # log log { output file /var/log/caddy/staging.log } } ops.1123-jaune-1.wns.wilders.dev { # Redirect request to webhook service running on port 9000 reverse_proxy localhost:9000 # log log { output file /var/log/caddy/ops.log } }
-
// webhook.conf
[
{
"id": "update-staging",
"execute-command": "/home/wns_student/apps/oros/staging/fetch-and-deploy.sh",
"command-working-directory": "/home/wns_student/apps/oros/staging/"
},
{
"id": "update-prod",
"execute-command": "/home/wns_student/apps/oros/prod/fetch-and-deploy.sh",
"command-working-directory": "/home/wns_student/apps/oros/prod/"
}
]
\newpage
Securité de l’application
La securité d’une application est extrêmement importante. On ne peut pas penser à la création d’une application quelconque sans se soucier de la protection de l’application, mais surtout des données des clients. Voici ce que nous avons mis en place pour la securité de notre application :
- TypeORM : ORM veut dire Object-Relational Mapping, c’est une bibiliothèque pour TypeScript/JavaScript qui permet aux développeurs d’interagir avec les bases de données en utilisant une méthode orientée objet. Voici les raisons pour lesquelles elle peut être utile pour la sécurité :
- Prévention d’injection SQL : comme elle sépare les données des commandes, cela aide à éviter les attaques par injection SQL
- Validation des données : TypeORM supporte les décorateurs pour validation, ce qui permet de mettre des contraintes sur les propriétés Entité (par exemple des champs obligatoires, des valeurs uniques), ce qui assure que seules des données valides sont sauvegardées dans la base de données.
- Gestion de relation entre Entités : comme elle gère les relations par Entité, cela reduit le risque d’exposer des données sensibles par accident en faisant des requêtes complexes. On peut contrôler quelles données sont récupérées.
- Options de connexion : TypeORM permet de configurer les options de connexion d’une façon sûre, y compris l’utilisation de variables d’environnement pour les données sensibles (comme les identifiants de base de données), ce qui permet de les séparer du code source.
- Eager / Lazy Loading : TypeORM supporte eager loading ainsi que lazy loading, ce qui permet de contrôler quand les données sont récupérées, ce qui peut réduire les chances d’exposer des données non nécessaires et la surface d'attaques.
- JSX : Comme nous utilisons Next et React pour notre application, nous avons écrit en JSX. Même si le JSX est une extension de syntaxe pour JavaScript avec React pour décrire comment l’UI devrait être, il peut également contribuer à la sécurité d’une application :
- Échappement automatique : le JSX échappe automatiquement les valeurs insérées dans le markup. Cela aide à empêcher des attaques Cross-Site Scripting (XSS) car n’importe quel contenu généré par un utilisateur est traité comme texte simple, et pas du code potentiellement exécutable.
- Architecture basée sur les composants : Comme il encourage une approche modulaire, le JSX encourage une meilleure organisation de code. Cette séparation peut aider en isolant et en gérant les préoccupations de sécurité dans des parties plus petites et maintenables.
- Rendu Contrôlé : React permet de contrôler comment les composants sont rendus en se basant sur state et props. Cela veut dire qu’on peut rendre du contenu sous conditions, ce qui peut être utile pour implémenter des mesures de sécurité (par exemple cacher des informations sensibles en fonction des rôles d’utilisateur).
- Validation de Props : Utiliser TypeScript avec JSX peut aider à s’assurer que les composants reçoivent les types de données attendus, ce qui réduit le risque d'erreurs d'exécution ou un fonctionnement inattendu qui peut créer des failles de sécurité.
- Argon2 : C’est un algorithme de hachage que nous avons utilisé pour les mots de passe utilisateurs, et cela rehausse la sécurité de plusieurs manières :
- Fonction Memory-Hard : Argon2 est créé pour obliger une grande quantité de mémoire pour calculer les hachages, ce qui le rend résistant à des attaques de force brute utilisant du matériel informatique dédié comme des GPUs et ASICs. Cela veut dire que les personnes voulant faire une attaque doivent investir dans des ressources très coûteuses s’ils veulent concrétiser une attaque.
- Résistance à des attaques par canal auxiliaire : Le design d’Argon2 aide à mitiger les risques d’attaques par canal auxiliaire, comme des attaques temporelles, en étant moins prévisible et plus consistant dans sa performance.
- Salting intégré : Argon2 incorpore automatiquement un sel dans le processus de hachage, ce qui assure que même si 2 utilisateurs ont le même mot de passe, leur hachages seront différents. Cela évite des attaques de hachages pré-calculés, comme les rainbow tables.
- Jose (Javascript Object Signing and Encryption): C’est un module JavaScript qui fournit plusieurs fonctionnalités qui rehaussent la sécurité, particulièrement dans la manipulation des JWT (JSON Web Tokens) et autres protocoles de messagerie :
- Création et Vérification des JWTs : Jose permet de créer et vérifier facilement des JWTs pour l’authentification et l'autorisation.
- Signature et Chiffrement : La bibiliothèque supporte la signature (assurant l’intégrité des données et l’authencitié) et le chiffrement (assurant la confidentialité des données).
- Support de Multiples Algorithmes : Les algorithmes cryptographiques comme HMAC, RSA et ECDSA sont disponibles, permettant le choix selon ce qui est le plus approprié.
- Gestion des clés : La bibiliothèque fournit des outils pour la gestion des clés, comme le support de la rotation de clés et de divers formats de clés.
- Express Middleware : C'est un composant d'ExpressJs, un framework pour NodeJs qui facilite le développement d'applications. Le middleware est une fonction qui a accès à l'objet de requête (req), à l'objet de réponse (res) et à la fonction next dans le cycle de traitement des requêtes :
- Validation et Correction des Entrées : Le middleware peut valider et corriger des requêtes pour assurer que leurs données sont propres et qu’elles sont au format attendu, aidant à empêcher des attaques comme des injections SQL ou XSS.
- Authentification et Autorisation : Le middleware peut gérer l’authentification d’utilisateur (par exemple en vérifiant des jetons) et l’autorisation en assurant que les utilisateurs ont la permission d’accéder à certaines ressources, et cela aide à sécuriser les endpoints.
- Rate limiting : Le middleware peut limiter le nombre de requêtes qu’un utilisateur peut faire dans un certain intervalle de temps, aidant à éviter l’abus et des attaques de type DDOS.
- Gestion de CORS : Le middleware peut gérer les paramètres de Cross-Origin Resource Sharing (CORS) pour contrôler quels domaines peuvent accéder aux ressources, ce qui empêche des accès illégitimes.
- Les En-têtes de sécurité : Le middleware peut ajouter des en-têtes de sécurité HTTP aux réponses, ce qui ajoute une couche supplémentaire de sécurité contre les attaques.
- Gestion des Sessions : Le middleware peut gérer les cookies de session et implémente des mesures de sécurité comme l'expiration des cookies et secure flags pour protéger les données de session.
Annexe (diagramme de classes)
{height=95%}